

INTRODUCCIÓN
Amazon ECS y EKS son servicios de orquestación de contenedores de la plataforma de servicios en la nube de Amazon, ambos tienen el mismo objetivo, poder desplegar y administrar aplicaciones mediante una arquitectura de contenedores en la nube de una forma sencilla y escalable, la diferencia entre en servicio y otro radica en que Amazon EKS es la versión de la herramienta de Kubernetes con la ventaja de que EKS se encuentra integrada con el resto de servicios de Amazon como EC2, ECR, ...
CONTENEDORES
No se puede hablar de ECS O EKS sin hablar previamente de los contenedores, tecnología de la que surge posteriormente una forma de manejarlos y escalarlos. Los contenedores son unidades de software que aíslan software del resto del sistema permitiendo de esta forma empaquetar aplicaciones junto al entorno que estas necesitan. A continuación, se muestra una comparación con su alternativa tradicional, las maquina virtuales:
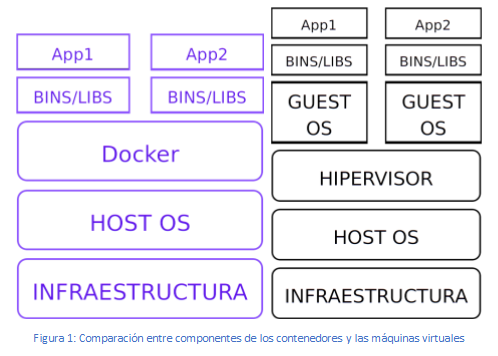
En la figura 1, puede verse una comparación entre los contenedores y las máquinas virtuales. Mientras que las máquinas virtuales se apoyan en la tecnología del hipervisor para simular el hardware y sobre éste, se ejecutan los sistemas operativos, los contenedores no realizan dicha simulación, sino que empaquetan un conjunto de procesos para aislarse del resto del sistema, pero ejecutándose cada contenedor sobre el propio Kernel del sistema operativo anfitrión.
Por otro lado, mientras que las máquinas virtuales permiten tener un sistema operativo completo, incluyendo un kernel propio y con recursos específicos, tienen la contrapartida de ser mucho más pesadas en comparación con los contenedores, los cuales consumen muchos menos recursos.
Los contenedores tienen sus raíces en los sistemas Unix, creado por Dennis Ritchie y Ken Thompson como un sistema monousuario para el minicomputador PDP-7. En Unix v7, se crea el comando chroot que permite cambiar el directorio raíz de un proceso junto a sus hijos. Este comando fue el que inició la separación de procesos.
Posteriormente, en los años 2000, un proveedor de entornos de FreeBSD, sistema operativo basado en Unix, creó las jaulas que permitían dividir un sistema FreeBSD en varios. Un año más tarde surge Linux VServer, éste, basado en el sistema de jaulas, permitía dividir los recursos de un sistema tales como el sistema de archivos, el tiempo de CPU, ... Esto último ya se va pareciendo más a un contenedor.
La evolución continúa hasta que, en 2008, son lanzados en Linux los cgroups o control groups. Se trata de una forma de asignar a un conjunto de procesos el mismo limite en cuanto a asignación de recursos se refiere, por ejemplo, limites en cuanto al uso de memoria, uso de cpu, ...
La evolución de los contenedores sigue progresando, y, con ella, nuevas herramientas alrededor de ésta.
Lo que está claro es que toda esta tecnología se debe a los sistemas Unix como FreeBSD, Solaris o Linux, sistemas operativos que, apoyándose en los conceptos proporcionados por Unix, permitieron el desarrollo gradual de esta tecnología.
ORQUESTACIÓN DE CONTENEDORES
Administrar una aplicación formada por una arquitectura de microservicios puede llegar a realizarse de forma manual si la aplicación es lo suficientemente pequeña y no es demasiado compleja, el problema surge cuando la aplicación se hace lo suficientemente grande y compleja, es decir, cuenta con un gran número de diferentes servicios en los que cada servicio se requiere que se encuentre en alta disponibilidad, tolerante a fallos y que además determinados servicios dependientes entre si se coordinen. La administración de contenedores abarca todo su ciclo de vida (aprovisionamiento, programación, despliegue y eliminación) y mediante los orquestadores puede automatizarse todo este ciclo ayudando a simplificar su administración.
Google fue de los primeros que se dio cuenta que administrar de forma manual el despliegue de aplicaciones junto con su posterior mantenimiento no era una tarea trivial, por ello, durante muchos años desarrollaron Borg como una herramienta para gestionar miles de aplicaciones a través de clústeres cada uno con miles de máquinas, en un principio escrito en C++ y posteriormente en GO, fue presentado en 2014 mediante una versión de código abierto que tuvo rápidamente una amplia adopción.
AMAZON ECS
Amazon ECS (Elastic Container Service) es un servicio para la orquestación de contenedores en la nube publica de Amazon que se integra fácilmente con otros servicios ofrecidos por este proveedor como Amazon EC2, Fargate, ... Además de aprovecharse de la infraestructura global de Amazon proveyendo seguridad escalabilidad, rendimiento, ...
La arquitectura de Amazon ECS está formada por tres componentes principales: Las definiciones de las tareas, los servicios y los clusters. La definición de una tarea (Task Definition) es un archivo JSON que especifica la arquitectura a crear, entre otros parámetros se encuentran, la imagen Docker que va a utilizar cada contenedor, la cantidad de recursos que va a tomar la tarea, los límites de uso de recursos de cada contenedor, el mapeo de puertos de los contenedores, ... Los servicios, agrupan tareas de las cuales debe mantenerse un número determinado ejecutando y en el caso de que alguna falle, se lance otra instancia de forma automática. Los clusters son agrupaciones de tareas y servicios, en él se especifican configuraciones y capacidad compartida por las tareas y servicios que este contiene, además, un cluster puede extenderse por diferentes zonas de disponibilidad de una misma región.
Un concepto importante a tener en cuenta en los servicios de Amazon ECS es el de los proveedores de capacidad, un proveedor de capacidad administra el escalado de la infraestructura para las tareas de los clusters, por ejemplo en el caso de que el proveedor de capacidad sean instancias de EC2 se usara un grupo de autoescalado que mantendrá el número de instancias en las que se va a ejecutar las tareas entre unos valores mínimos y máximos, y en el caso de que se caiga alguna instancia y se quede por debajo del mínimo, levantara otra mediante una plantilla de instancias de EC2. El proveedor en particular puede ser Fargate o grupos de autoescalado automático y estos están asociados al cluster. Además de especificar el proveedor o proveedores de capacidad que el cluster puede usar, al
lanzar una tarea se puede lanzar directamente a uno de los proveedores (tipo de lanzamiento) o mediante una estrategia, en la estrategia, se deberá especificar dos valores, la base que es el mínimo de tareas que deben ejecutarse en dicho proveedor (por defecto 0), y el peso que determina el porcentaje relativo del número total de tareas a lanzar sobre dicho proveedor. Un ejemplo de esto último seria, teniendo dos proveedores de capacidad, proveedor 1 y proveedor 2, donde al proveedor 1 se le especifica una base de 2 y un peso de 1 y al proveedor dos se le especifica una base de 0 y un peso de 3, entonces una vez se satisfaga la condición de 2 tareas en el proveedor 1, por cada tarea en el proveedor 1 habrá tres en el proveedor 2.
El proveedor de capacidad especifica además de cómo se va a escalar la infraestructura, donde se van a ejecutar las instancias de las taras, en el caso de Fargate las instancias de las tareas se ejecutarán en una arquitectura serverless y en el caso de EC2, las tareas se ejecutarán en las instancias de EC2 mantenidas por el proveedor de capacidad.
Otro componente a mencionar de Amazon ECS es el ECS Agent, este se encuentra en cada una de las instancias de EC2 con AMI’s optimizadas para ECS, aunque también se puede instalar en cualquier AMI que no disponga de este de forma manual, este componente permite obtener datos de telemetría de las instancias de EC2 como por ejemplo el uso de recursos que está haciendo la tareas de la instancia, mediante el ECS Agent ECS puede parar y arrancar tareas a petición y además, el ECS Agent puede interactuar con la API de Amazon y Docker aportando de esta forma el control de ECS sobre las instancias.
EJERCICIO 1
Mediante este ejercicio se pretende crear un cluster en una zona de disponibilidad mediante instancias de EC2 que ejecute un contenedor de nginx, a continuación, se muestra una imagen con la arquitectura que se quiere implementar:
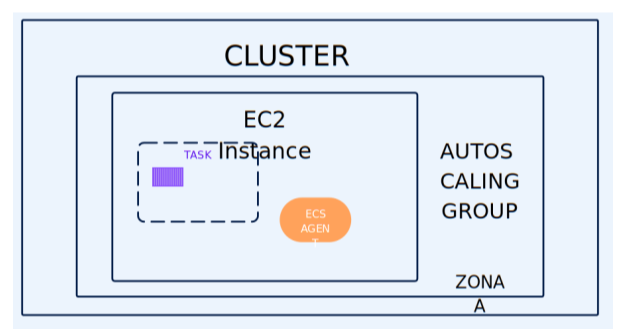
Uno de los fallos principales son los roles de IAM, por defecto tenemos varios roles por defecto AWSServiceRoleForECS, AWSServiceRoleForSupport, AWSServiceRoleForTrustedAdvisor, ... Uno de los permisos de IAM que hay que añadir es AWSServiceRoleForAutoScaling. Otro fallo importante es en la definición de la tarea, ya que la capacidad de la tarea no puede superar a la de la instancia de EC2, una t2.micro tiene una capacidad de 1vCPU y 1GB de RAM. Otro permiso importante a introducir es ecsInstanceRole, este rol aplica la política AmazonEC2ContainerServiceforEC2Role que permite a instancias de EC2 en un Cluster ECS acceder a ECS, por ello, este permiso es muy importante.
En primer lugar, nos dirigimos al servicio de ECS y dentro de este al apartado de Definición de tareas que puede encontrarse en la barra lateral de navegación, una vez dentro pulsamos sobre el botón de Crear una nueva definición de tarea y se abrirá un formulario para definir dicha tarea.
Primero se debe dar un nombre a la familia de la definición de la tarea, esto se utilizará para agrupar versiones de la misma tarea ya que todas estas aparecerán bajo este mismo nombre, en nuestro caso la llamaremos nginx.
Posteriormente se definirá el tipo de lanzamiento, como se ha mencionado anteriormente, este indicara la infraestructura en la cual se lanzarán las instancias de las tareas, en este caso instancias de Amazon EC2.
A continuación, se especifica el modo de red por defecto, el modo de red, indica que tipo de red usan los contenedores de las tareas, el que se encuentra por defecto seleccionado es awsvpc, el cual permite seleccionar la configuración de red, grupos de seguridad y si se debe asignar una ip publica a la tarea.
Posteriormente, se especifica el tamaño de la tarea en general, este tamaño será compartido por los contenedores de la tarea, para especificar el tamaño de la tarea se define la cantidad de CPU y de memoria, la cantidad de CPU se mide en virtual CPU (vCPU) donde 1 vCPU equivale a 1024 unidades
de CPU mientras que la memoria se especifica en GB. Un aspecto importante a tener en cuenta es que para las tareas ejecutadas en instancias de EC2, si el Cluster en el que se ejecuta la tarea no tiene instancias de contenedor registradas con las unidades de CPU solicitadas, la tarea no funciona, en este caso se especifica 1vCPU y 3GB de memoria.
En el apartado de Rol de tarea y Rol de ejecución de tareas especificamos ninguno, este apartado asigna un rol con permisos de IAM que permitan para el primer apartado realizar llamadas a la API de AWS por los contenedores y para el segundo apartado que el agente ECS de la instancia de EC2 pueda realizar llamadas a la API de AWS.
Para el apartado de contenedor, especificamos el nombre que se va a dar al contenedor, en este caso nginx, la URI de la imagen, en este caso nginx:latest y lo marcamos como contenedor esencial.
Para el mapeo de puertos, dejamos especificado el 80, este mapeara el puerto 80 del contenedor con el 80 del host.
Como límites estrictos de asignación de recursos al contenedor, especificaremos los mismos que para la tarea.
Los demás apartados se dejarán por defecto y al final del todo se podrá pulsar sobre Crear tarea.
A continuación, nos iremos al apartado del Cluster y pulsaremos sobre Crear Cluster, al pulsar, nos aparecerá un formulario de creación en el cual deberá especificarse el nombre del cluster en primer lugar.
Posteriormente nos iremos al apartado de infraestructura y seleccionaremos como infraestructura instancias de Amazon EC2, una vez pulsado se desplegará un apartado donde se deberá especificar un grupo de autoescalado nuevo, se seleccionará un modelo de aprovisionamiento bajo demanda, como sistema operativo un Amazon Linux 2023 y como tipo de instancia una t2.micro, como capacidad deseada (número de instancias que se van a lanzar en el cluster) se especificara como mínimo uno y como máximo uno.
En el apartado de configuración de red se deberá especificar el campo Asignar automáticamente una IP publica como Encender ya que, si no, no nos asignara ip a la instancia de EC2. Por último, pulsamos sobre crear y esperamos a que se cree el cluster.
EJERCICIO 2
En este ejercicio se pretende tener dos contenedores replicando el servidor de nginx en dos zonas de disponibilidad distintas y mediante un balanceador de carga dar acceso al servidor a través de cualquiera de las dos instancias.
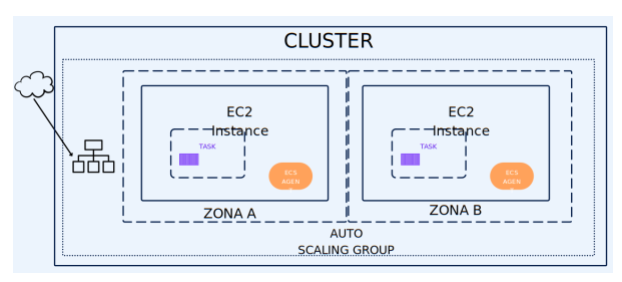
En este ejercicio se utilizarán nuevos servicios y conceptos necesarios para hacer funcionar el ejercicio.
En primer lugar, nos dirigimos al servicio de ECS y pulsamos en Crear cluster, daremos el nombre al cluster y como infraestructura elegiremos Instancias de Amazon EC2, a continuación, configuramos el grupo de autoescalado mediante un modelo de aprovisionamiento bajo demanda, como sistema operativo un Amazon Linux 2023, en tipo de instancia elegiremos una t2.micro y como capacidad deseada se seleccionara un mínimo de dos y un máximo de dos, esto es porque queremos dos instancias de EC2 en las cuales ejecutaremos una instancia de la tarea en cada una, elegiremos el par de claves y como configuración de la red se elegirá la red por defecto con dos zonas de disponibilidad y el grupo de seguridad creado en el ejercicio anterior, es importante que se marque en la configuración de red para instancias de Amazon EC2 encender en el campo de asignar automáticamente una IP pública. Pulsaremos sobre crear y esperaremos a que se cree el cluster.
Para la tarea a ejecutar se usará la del ejercicio anterior. Una vez creado el cluster se nos creara en el servicio de EC2 el grupo de escalado especificado que lanzara las instancias definidas en este, en este caso dos instancias de EC2.
A continuación, se creará un grupo de destino que será usado por el balanceador de carga para redirigir el tráfico alternativamente a cada una de las instancias. Para crear el grupo de destino nos dirigimos al apartado de Equilibrador de carga y dentro de este a Grupos de destino, una vez aquí pulsaremos sobre Crear u grupo de destino, como tipo de destino se seleccionará de tipo instancias, se le dará un nombre y todo lo demás se dejará por defecto, después se pulsará sobre siguiente y se registraran las instancias en el grupo de destino seleccionándolas y pulsando sobre Incluir como pendiente a continuación, por último, se pulsará en Crear grupo de destino.
Creado el grupo de destino nos aparecerá un resumen de este y en la esquina superior derecha un botón de acciones se pulsará sobre este botón y en el menú desplegable sobre Asociar un balanceador de carga nuevo, en el formulario de configuración, se le dará un nombre, se dejara como expuesto a internet y como tipo de direccionamiento IPv4, en el mapeo de red se seleccionaran las zonas de disponibilidad donde se encuentran las instancias, en grupos de seguridad se seleccionara el creado en el ejercicio anterior y en agentes de escucha y direccionamiento se seleccionará el grupo de destino previamente creado, por último se pulsara sobre Crear balanceador de carga.
Posteriormente, nos dirigiremos al servicio de ECS y seleccionaremos el cluster creado, nos iremos al apartado de tareas y pulsaremos sobre ejecutar una nueva tarea, como tipo de lanzamiento elegimos EC2, en configuración de la implementación seleccionamos Tarea, seleccionaremos la familia de la
tarea creada en el primer ejercicio y como numero de tareas deseadas dos. Por último, seleccionaremos una estrategia de colocación para que estas tareas se repartan entre las distintas instancias, para ello, seleccionaremos una tarea por host y pulsaremos sobre Crear.
Una vez creadas las tareas se lanzarán cada una en una instancia de EC2, para comprobar que funciona iremos al apartado del balanceador de carga y copiaremos el dns, lo pegaremos sobre la barra del navegador y se podrá comprobar que accede normalmente a la página de nginx.
Por último, para comprobar que se han repartido correctamente las tareas, se accederá al grupo de auto escalado creado por el cluster y se modificará el mínimo de instancias a una, esto se hace para que al eliminar una de las dos instancias el grupo de autoescalado no cree otra automáticamente. Iremos al apartado de instancias y terminaremos una de las dos instancias. Una vez terminada la instancia quedando solo una ejecutado, recargaremos la página de nginx y comprobaremos que se sigue ejecutando.
En este ejercicio se han visto nuevos conceptos como la estrategia de colocación habiendo tres tipos principales de estrategias: Binpack reparte las tareas de forma que quede la cantidad mínima de recursos sin utilizar, random y spread que se reparte en función de diferentes especificaciones como las zonas de disponibilidad o las diferentes instancias. También se ha visto como ejecutar varias instancias de tareas y como combinar ECS con otros servicios.


{kind=link}